• Spark 實戰:大數據效能調校、資料傾斜處理與 Iceberg 資料湖整合
內容包含:
- Spark 效能調校: 掌握 Memory Tuning、高效能 Join 策略,並實作 DataFrame 與 Dataset 的應用
- 資料傾斜處理: 學習並應用 Salting 等技巧,解決分散式運算中的效能瓶頸
- 資料湖整合: 結合 Iceberg Table Format,管理並操作本地端的分區資料。
如果想要認證放在 Linkedin,要到官網完成所有課程和繳交作業
什麼是 Apache Spark?
Apache Spark 是一個分散式計算框架,旨在高效地處理非常大量的資料。它被視為 Hadoop 和 Java MapReduce 等早期大數據技術的後繼者
可以把它想像成一個擁有許多工人(Executor)的工頭(Driver),能夠將一個複雜的任務(例如分析 100TB 的資料)分解成許多小任務,並分配給所有工人同時執行,大幅提升效率
Spark 的核心優勢在於它能將運算過程儲存在記憶體中,比傳統的 MapReduce 寫入硬碟的方式快很多
Spark 的三大核心概念
RDD vs. DataFrame (資料處理的演進)
| 特性 | RDD (Resilient Distributed Datasets) | DataFrame |
|---|---|---|
| 資料結構 | 無結構,類似於分散式的 Java/Scala/Python 物件集合 | 結構化,類似於帶有欄位名稱的資料表 |
| 優點 | 靈活度高,可以處理任何格式的資料(包含非結構化的純文字、圖片) | 效能高,因為有 Catalyst 優化器會自動最佳化查詢 |
| 缺點 | 效能較低,因為 Spark 無法理解資料的內部結構,無法進行優化 | 僅限於結構化與半結構化資料 |
| API | 提供了低階轉換(map、filter)和動作(collect、reduce) |
提供了高階 API(如 select、where、groupBy、join),類似 SQL |
| 類型安全 | 編譯時型別安全(在 Scala/Java 中) | 弱類型,主要靠欄位名稱 |
| 依賴與聚合 | – 窄依賴 (Narrow dependency):每個 parent partition 對應少數 child(例:map、filter)– 寬依賴 (Wide dependency):child partition 需要 shuffle(例: groupByKey、reduceByKey),會觸發 shuffle → 成本高。– GroupByKey:所有同 key 的資料都要 shuffle 到同一個節點 → 成本高、容易 OOM。 – ReduceByKey:先在本地 combine,再 shuffle → 更高效。 |
Catalyst 自動判斷 query plan,減少 shuffle,並選擇最佳執行方式 |
| 分區控制 | – coalesce(n):減少分區數,不 shuffle,快但可能不均勻,常用於輸出前避免小檔案。 – repartition(n):增加或減少分區數,一定 shuffle,資料更平均但成本較高。 |
DataFrame 同樣支援 coalesce() 和 repartition(),用法與效果一致 |
| 資料讀取 | sc.textFile()、wholeTextFiles() |
spark.read.csv/json/parquet/orc/jdbc;支援 HDFS、S3、GCS 等儲存系統 |
| Schema 管理 | 無 schema,需要自行解析字串或物件 | – Schema Enforcement:用 StructType 明確指定欄位型別,避免推斷錯誤– Read Modes: PERMISSIVE(預設)、DROPMALFORMED、FAILFAST,控制壞資料處理方式 |
| Transformation / Action | map、filter、flatMap(transformation);collect、count(action) |
select、where、withColumn(transformation);show、count、write.save(action) |
| 資料寫入 | RDD 轉文字檔 saveAsTextFile() |
df.write.mode("append/overwrite").format("parquet").partitionBy("dt");常用 Parquet/ORC |
| 操作與效能 | 需要手動優化(如調整分區、避免 shuffle) | Catalyst + Tungsten 自動優化;支援 explain() 查看 query plan |
| 資料型別處理 | 基本型別(字串、數字);需手動處理 JSON/結構化 | – cast() 轉型– fillna()/dropna() 缺值處理– 複合型別: ArrayType、MapType、StructType– JSON 處理: from_json()/to_json()– 拆解: explode() |
| 日期與時間 | 沒有內建支援,需要自己 parse | – to_date()、to_timestamp()、date_format()– datediff()、add_months()、last_day()– 時區設定: spark.sql.session.timeZone |
| 快取與暫存 | – cache() = persist(MEMORY_ONLY),適合重複查詢– persist() 可選多種層級(MEMORY、DISK、SER)下面解說 |
DataFrame 與 Table 都支援 cache() / persist() / unpersist();也可用 spark.catalog.cacheTable("table") 快取整張表 |
| 適用場景 | 需要對資料進行低階、客製化操作,或處理非結構化資料時 | 絕大多數的 ETL、批次分析、機器學習等結構化資料處理任務 |
| 演進 | Spark 1.0 版本的主要核心 | Spark 2.0 版本開始推廣,並成為主流 |
Driver vs. Executor (工頭與工人的關係)
Spark 應用程式由一個 Driver 和多個 Executor 組成,這就是分散式運算的基礎
| 角色 | Driver (驅動程式) | Executor (執行器) |
|---|---|---|
| 任務 | 負責統籌規劃,將任務分解成多個階段和任務,並分配給 Executor 執行 | 負責實際執行運算,處理由 Driver 分配的小任務。 |
| 比喻 | 建築工地的工頭,規劃建築藍圖並分配工作給工人 | 建築工地的工人,負責砌磚、搬運等實際工作 |
| 運作 | 當你提交一個 Spark 應用程式時,Driver 就會啟動,與叢集管理器(如 YARN 或 Kubernetes)協調,以獲得 Executor 的資源 | 每個 Executor 都有自己的 CPU 核心和記憶體,獨立執行任務並回報結果給 Driver |
分散式運算原理 (協同工作的核心流程)
提交一個 Spark 任務時,背後會發生以下流程:
| 階段 | 核心動作 | 說明 |
|---|---|---|
| 1. 任務提交 | 啟動 Driver | 使用 spark-submit 啟動 Spark 應用程式,並啟動作為工頭的 Driver |
| 2. 資源協調 | 申請 Executor | Driver 與叢集管理器溝通,申請所需的 Executor (工人) 資源 |
| 3. 任務分解 | 建立執行計畫 | Driver 將複雜的任務(如 JOIN 或 GROUP BY)拆解成多個階段 (Stages) 和更小的任務 (Tasks) |
| 4. 任務執行 | 分配與運算 | Driver 將任務發送到每個可用的 Executor,由它們平行處理分散在不同節點上的資料 |
| 5. 結果回傳 | 收集結果 | Executor 完成任務後,將結果回傳給 Driver,或將中間結果暫存在記憶體/硬碟中,供後續階段使用 |
假設我要做一個資料管道,可能會是
json file → Kafka → Spark 批次處理資料 → GCS 檔案 → BigQuery → windows 分析後存入 postgresql
下面課程示範為「Spark 批次處理資料」階段:(本地端 docker 容器)建立 SparkSession -> 讀表 → 加鹽聚合 → 寫回 Iceberg 表 -> 觀察處理是否真的改善
Spark 記憶體調整(Memory Tuning)
| 參數名稱 | 中文說明 | 詳細解釋 |
|---|---|---|
spark.executor.memory |
每個 Executor 可使用的記憶體大小 | 設定太小會導致 Spark 必須將資料「spill to disk」(寫到磁碟),導致速度大幅變慢。講師建議透過嘗試不同值(例如 2、4、6、8GB),找到能穩定運行且最小的值,以避免記憶體浪費 |
spark.executor.cores |
每個 Executor 可使用的 CPU 核心數 | 控制每個 Executor 同時能執行多少 task。預設是 4,講師建議不超過 6,避免資源爭用 |
spark.executor.memoryOverheadFactor |
Executor 記憶體的額外保留比例 | 這是保留給非 heap 記憶體用途(例如 shuffle buffer、序列化、UDF 中 native 操作等),預設是 10%。如果 job 很複雜,或使用大量 UDF,講師建議加大這個比例 |
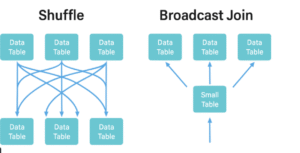
Join 策略
Spark 主要支援三種類型的連接操作
| Join 類型 | 適用條件 | 原理 | 效能特性 | 限制 / 注意事項 | 案例 |
|---|---|---|---|---|---|
| Shuffle Sort Merge Join (洗牌排序合併連接) |
幾乎所有情況 | 依連接鍵 Shuffle 資料到各執行器 → 每個執行器內排序與合併 | 最不高效,但最通用 | Shuffle 是 Spark 擴展性瓶頸,大量資料(>20-30TB/天)成本極高 | — |
| Broadcast Hash Join (廣播雜湊連接) |
其中一側資料集很小(~8-10GB 以內) | 小表廣播到所有執行器,避免 Shuffle | 非常高效,節省網路與磁碟 I/O | 小表過大(例如 IPv6 查找表)時無法廣播 | Netflix:處理 100TB/h 流程中廣播數 GB 的 IP 查找表 |
| Bucket Join (分桶連接) |
兩表均已按連接鍵分桶 | 預先按鍵分桶 → 相同桶號直接匹配 → 無 Shuffle | 巨大效能提升 | 建桶需成本,適用多次 Join/聚合場景;桶數建議 2 的冪次方;避免過多空桶 | Facebook:10TB 與 50TB 資料,1024 桶,將 Shuffle Join 轉為高效 Bucket Join |
是否該使用 Broadcast Hash Join?
小表被很多任務重複廣播且經常變動,導致網路壓力大,這時可考慮 cache 小表,或落地成維度表
spark.conf.set("spark.sql.adaptive.enabled", "true")
# 調整自動廣播門檻
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "256MB")
Notebook 模式 vs Spark Server
| Notebook 模式 | Spark Server 模式 |
|---|---|
| Session 一直開著,變數和 cache 會一直留 | 每次 run 都是新的 Application |
容易忘記 unpersist() 導致記憶體佔滿 |
不會留舊 cache,乾淨環境 |
| 適合探索資料(EDA) | 適合正式任務、批次處理、測試 |
Spark 暫存與快取機制比較
| Spark 行為 | 說明 |
|---|---|
| Temporary View | 儲存查詢邏輯,每次都重新計算 |
| Cache (MEMORY) | 把資料結果暫存在記憶體,重複使用時不用重算 |
| Cache (DISK) | 把 DataFrame 序列化後,檔案寫到磁碟,下次用的時候直接從磁碟讀 |
| unpersist() | 在 Notebook 模式(像 Jupyter、Databricks Notebook),快取資料會一直佔記憶體,要手動處理 |
Parquet(檔案格式與排序)
| 功能 / 建議 | 說明 | Pandas 對照理解 |
|---|---|---|
| Parquet 格式 | 支援壓縮(Run-length encoding),非常適合大資料儲存 | Pandas to_parquet(),比 to_csv() 更省空間、更快讀寫 |
不要用 .sort() 全域排序 |
全域排序會非常慢,因為 Spark 要在多節點間移動資料(Shuffle) | Pandas sort_values() 對超大 DataFrame 在單機很慢一樣,但這裡還要跨機器傳資料 |
改用 .sortWithinPartitions() |
只在每個分區內排序,能並行處理,速度快 | Pandas groupby(..., sort=False) + 再對每組內排序,避免全表排序 |
如何處理資料傾斜(某個partiton過大)? 兩種常見解法(AQE vs. Salting)
當某個分區(或 Executor)獲得的資料量遠多於其他分區時,就會發生資料傾斜 (Data Skew),這會導致效能瓶頸。我們可以採用兩種常見策略來應對:
- 解法 1: AQE (自適應查詢執行) — 這是自動化的智慧優化
- 解法 2: Salting (群組鹽值法) — 這是手動的程式碼調整
解法 1:Adaptive Query Execution(AQE,自適應查詢執行)
AQE 是 Spark 2.x 版之後內建的智慧功能,能自動偵測並優化執行計畫
當開啟功能後,Spark 在執行 GROUP BY 或 JOIN 時,若發現資料傾斜,它會:
- 動態切分大分區:自動將資料量異常龐大的分區(例如某個 user_id)切分成多個小分區
- 動態調整分區數:根據資料的實際大小(例如 10MB),自動調整 Shuffle 之後的分區數量,確保每個執行器的工作量更平衡
啟用 AQE 總開關
spark.conf.set("spark.sql.adaptive.enabled", "true")
處理 Join/Aggregate 資料傾斜,自動判斷切分 _1、_2…
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
設定每個分區的最佳大小,讓 Spark 自動調整分區數量
這裡設定為 64MB,意味著 Spark 會盡量讓每個分區的輸出大小接近 64MB
spark.conf.set("spark.sql.adaptive.shuffle.targetPostShuffleInputSize", "64MB")
當執行以下 SQL 時,Spark 會在後台自動判斷哪個 user_id 存在資料傾斜,並進行分片處理,我們不需要修改程式碼
SELECT user_id, COUNT(*) AS interaction_count
FROM social_media_events
GROUP BY user_id
解法 2:Salting the GROUP BY(群組鹽值法)
Salting 是一種手動解決資料傾斜的方法。核心思想是:透過引入一個隨機值(salt),將原本傾斜的單一鍵值,分散到多個分區上進行平行處理,然後再進行第二次聚合
假設要對 user_id 做 groupBy 或 join,但某個用戶(例如 Beyoncé)資料多得不合理,導致 Spark 卡在那一個 partition,會造成資料傾斜
- 為傾斜的 user_id 欄位加上一個隨機數(例如 0-9),形成一個新的複合鍵 (user_id_salt)
# df.withColumn("salt", (rand() * 10).cast("int"))
df_salted = df.withColumn("salt", (rand() * 10).cast("int"))
df_salted.createOrReplaceTempView("salted_events")
- 對 salted key groupBy 並做第一次 aggregate,將工作分散到多個分區
# df.groupBy("user_id", "salt").agg(...)
CREATE OR REPLACE TEMP VIEW salted_agg AS
SELECT user_id, salt, COUNT(*) AS partial_count
FROM salted_events
GROUP BY user_id, salt
- 對第一次聚合的結果,再進行第二次聚合,但這次只使用原始的 user_id,將所有相同 user_id 的部分結果合併
# df.groupBy("user_id").agg(...)
SELECT user_id, SUM(partial_count) AS total_count
FROM salted_agg
GROUP BY user_id
如果是 AVG,就要先算 SUM 和 COUNT,最後再除
SELECT user_id, SUM(total_sum) / SUM(total_count) AS avg_value
FROM (
SELECT user_id, salt, SUM(metric) AS total_sum, COUNT(*) AS total_count
FROM salted_events
GROUP BY user_id, salt
) tmp
GROUP BY user_id
安裝 docker
docker-compose.yaml
- Spark(整合 Iceberg connector)
- REST API
- 模擬 S3 的物件儲存系統
- 容器啟動後自動初始化 MinIO bucket(warehouse),設定權限
“`=
version: “3”
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
- ./data:/home/iceberg/data
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
- 4040-4042:4040-4042
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
執行
```=
docker-compose up -d
實作
應用程式 → PostgreSQL (OLTP),這裡沒連接S3,用 csv 模擬資料示範
↓ (CDC/ETL)
S3 + Iceberg (Data Lake)
↓
Spark 大數據分析 → 結果存回 S3/PostgreSQL/csv
↓
BI 工具/儀表板
Iceberg 的作用是作為 資料湖的表格式 (Table Format),讓 S3 這種物件儲存變得像資料庫一樣好用
確認 pyspark 環境配置
import pyspark
print("pyspark version:", pyspark.__version__)
print("pyspark path :", inspect.getfile(pyspark))
![]()
![]()
設定 JAVA_HOME (下載路徑) + 設定環境變數
我自己有很多python環境,指定目前這個
import os, sys
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-17-openjdk-arm64"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
# 讓 driver / executor 都用現在這個 Python
os.environ["PYSPARK_PYTHON"] = sys.executable
os.environ["PYSPARK_DRIVER_PYTHON"] = sys.executable
print("JAVA_HOME =", os.environ["JAVA_HOME"])
![]()
Iceberg JAR 設定
ICEBERG_JAR = "/opt/spark/jars/iceberg-spark-runtime-3.5_2.12-1.8.1.jar"
# 檢查 JAR 檔案是否存在
if not os.path.exists(ICEBERG_JAR):
print(f"Iceberg JAR 檔案不存在: {ICEBERG_JAR}")
print("請再次確認")
else:
print(f"找到 Iceberg JAR: {ICEBERG_JAR}")
# 設置 Spark submit 參數
os.environ["PYSPARK_SUBMIT_ARGS"] = f"--jars {ICEBERG_JAR} pyspark-shell"
print(f"PYSPARK_SUBMIT_ARGS = {os.environ['PYSPARK_SUBMIT_ARGS']}")
啟動 Spark + Iceberg
假設兩個表,一個100MB、一個260MB
-
spark.sql.autoBroadcastJoinThreshold 門檻=256MB
- Spark 的判斷:Spark 會看到 100MB 的表小於 256MB 的門檻值,而 260MB 的表超過門檻
- Spark 的行動:Spark 會選擇最有效率的 Broadcast Hash Join。它會將 100MB 的表廣播到所有執行器上,並在這些執行器上與 260MB 的表進行連接
-
spark.sql.autoBroadcastJoinThreshold 門檻=50MB
- Spark 的判斷:Spark 會看到兩個表的大小(260MB 和 100MB)都超過了 50MB 的門檻值
- Spark 的行動:Spark 會放棄 Broadcast Join,退而求其次,改用 Shuffle Sort Merge Join。它會對兩個表都進行資料洗牌(Shuffle)和排序(Sort),這個過程會產生大量的網路傳輸和磁碟 I/O,導致任務效能下降。之後可以手動廣播,或一開始就使用 Bucket Join(分桶連接)
from pyspark.sql import SparkSession
from pyspark.sql.functions import to_timestamp, expr, col
spark = (
# 配置 Iceberg
SparkSession.builder
.appName("Jupyter-Iceberg-REST")
# --- 效能調校設定 ---
# 啟用 AQE(Adaptive Query Execution),讓 Spark 能動態優化
.config("spark.sql.adaptive.enabled", "true")
# 設定自動 Broadcast Join 的門檻,預設是 10MB
.config("spark.sql.autoBroadcastJoinThreshold", "256MB")
# 啟用 AQE 的資料傾斜處理
.config("spark.sql.adaptive.skewJoin.enabled", "true")
# --- 調整 memory ---
.config("spark.executor.memory", "4g")
.config("spark.executor.cores", "2")
# --- Iceberg 與 Catalog 設定 ---
.config("spark.sql.defaultCatalog", "spark_catalog")
# 加載 Iceberg 的 Spark 擴充功能
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
# REST catalog 配置(不使用 S3FileIO)
# .config("spark.sql.catalog.rest", "org.apache.iceberg.spark.SparkCatalog")
# .config("spark.sql.catalog.rest.type", "rest")
# .config("spark.sql.catalog.rest.uri", "http://iceberg-rest:8181")
# *** S3 相關配置,讓 REST 服務處理存儲 ***
# .config("spark.sql.catalog.rest.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
# .config("spark.sql.catalog.rest.s3.endpoint", "http://minio:9000")
# .config("spark.sql.catalog.rest.s3.path-style-access", "true")
# 啟用本地 spark_catalog
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.spark_catalog.type", "hadoop")
.config("spark.sql.catalog.spark_catalog.warehouse", "/tmp/iceberg-warehouse")
# 開啟 AQE(Adaptive Query Execution)
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
)
#
all_conf = dict(spark.sparkContext.getConf().getAll())
catalog_conf = {k: v for k, v in all_conf.items() if "catalog" in k.lower()}
print("\n=== Catalog 配置 ===")
for k, v in catalog_conf.items():
print(f"{k}: {v}")
# 測試兩個 catalog
print("\n=== 測試 Catalogs ===")
try:
catalogs = spark.sql("SHOW CATALOGS").collect()
print("可用的 catalogs:")
for catalog in catalogs:
print(f" - {catalog.catalog}")
except Exception as e:
print(f"列出 catalogs 失敗: {e}")
成功的話,會看到
+————–+
| catalog |
+————–+
| spark_catalog|
+————–+
這裡沒連sql,載入 CSV 模擬資料
events = spark.read.option("header", "true").csv("/home/iceberg/data/events.csv").withColumn("event_date", expr("DATE_TRUNC('day', event_time)"))
devices = spark.read.option("header","true").csv("/home/iceberg/data/devices.csv")
df = events.join(devices,on="device_id",how="left")
df = df.withColumnsRenamed({'browser_type': 'browser_family', 'os_type': 'os_family'})
df.show(
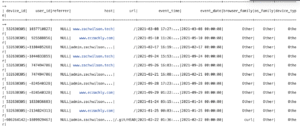
sorted = df.repartition(10, col("event_date"))\
.sortWithinPartitions(col("event_date"), col("host"))\
.withColumn("event_time", col("event_time").cast("timestamp"))
sortedTwo = df.repartition(10, col("event_date"))\
.sort(col("event_date"), col("host"))\
.withColumn("event_time", col("event_time").cast("timestamp"))
sorted.show()
sortedTwo.show()

建立 Iceberg 表
%%sql
SHOW CATALOGS;

%%sql
-- 使用本地 spark_catalog 創建 DB
CREATE NAMESPACE IF NOT EXISTS spark_catalog.test;
%%sql
SHOW NAMESPACES IN spark_catalog;

%%sql
DROP TABLE IF EXISTS spark_catalog.test.events;
%%sql
DROP TABLE IF EXISTS spark_catalog.test.events_sorted;
%%sql
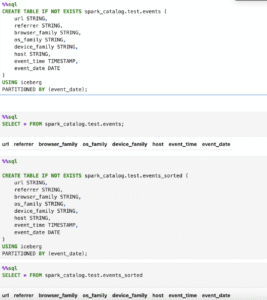
CREATE TABLE IF NOT EXISTS spark_catalog.test.events (
url STRING,
referrer STRING,
browser_family STRING,
os_family STRING,
device_family STRING,
host STRING,
event_time TIMESTAMP,
event_date DATE
)
USING iceberg
PARTITIONED BY (event_date);
%%sql
CREATE TABLE IF NOT EXISTS spark_catalog.test.events_sorted (
url STRING,
referrer STRING,
browser_family STRING,
os_family STRING,
device_family STRING,
host STRING,
event_time TIMESTAMP,
event_date DATE
)
USING iceberg
PARTITIONED BY (event_date);
%%sql
SELECT * FROM spark_catalog.test.events;
%%sql
SELECT * FROM spark_catalog.test.events_sorted
Spark 排序 + Iceberg 表寫入比較
from pyspark.sql.functions import col, to_timestamp
# 1
start_df = (df
.withColumn("event_time", to_timestamp("event_time"))
.withColumn("event_date", col("event_time").cast("date"))
.withColumnRenamed("device_type", "device_family") # ← 對齊表的欄位名
)
# 2 只挑表中需要的欄位
cols = ["url","referrer","browser_family","os_family","device_family","host","event_time","event_date"]
df_out = start_df.select(*[col(c) for c in cols])
# 3 分區後寫入(先分別排序,避免記憶體壓力)
df_out = df_out.repartition(10, col("event_date"))
df_out.writeTo("spark_catalog.test.events").overwritePartitions()
# check schema 一樣
first_sort_df = df_out.sortWithinPartitions(col("event_date"), col("browser_family"), col("host"))
first_sort_df.writeTo("spark_catalog.test.events_sorted").overwritePartitions()
%%sql
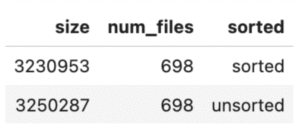
SELECT SUM(file_size_in_bytes) as size, COUNT(1) as num_files, 'sorted'
FROM spark_catalog.test.events_sorted.files
UNION ALL
SELECT SUM(file_size_in_bytes) as size, COUNT(1) as num_files, 'unsorted'
FROM spark_catalog.test.events.files
%%sql
SELECT SUM(file_size_in_bytes) as size, COUNT(1) as num_files
FROM spark_catalog.test.events.files;
實際觀察 Spark 執行計劃
%%sql
EXPLAIN SELECT count(*)
FROM spark_catalog.test.events
WHERE event_date < DATE '2022-01-01';

| 區塊 | 說明 |
|---|---|
AdaptiveSparkPlan |
啟用了 AQE(Adaptive Query Execution),表示 Spark 會依據實際資料調整計劃 |
BatchScan spark_catalog.test.events |
使用 Iceberg 的 V2 DataSource 進行批次掃描 |
filters=... |
event_date = ... 的查詢條件已成功被下推(Filter Pushdown) |
1754870400000000 |
是 2025-08-11 的微秒時間戳(Iceberg 內部格式) |
Filter(...) |
Spark 還會在執行時再做一次檢查(保險) |
groupedBy=[] |
無 group by 聚合,因此不需推入 Iceberg |
RuntimeFilters: [] |
未使用動態分區過濾(如 join filter) |
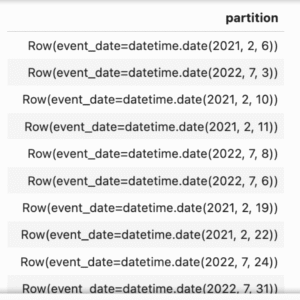
確認有多少不同partition(event_date)
%%sql
SELECT DISTINCT partition
FROM spark_catalog.test.events.files;
查看
%%sql
SELECT *
FROM spark_catalog.test.events
WHERE event_date = DATE '2021-02-06';
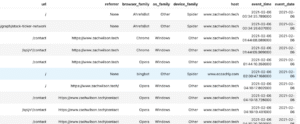
補充:暫存視圖(Temporary View)
若是今天想要 建立暫存視圖(Temporary View),可以註冊一個臨時的表,在後面引用
Temporary View
devices.createOrReplaceTempView("devices")
events.createOrReplaceTempView("events")
三種方式過濾掉 user_id 或 device_id NULL 的資料 (Dataset API vs DataFrame API vs Spark SQL)
// Dataset API
val filteredViaDataset = events.filter(event => event.user_id.isDefined && event.device_id.isDefined)
// DataFrame API
val filteredViaDataFrame = events.toDF().where($"user_id".isNotNull && $"device_id".isNotNull)
// Spark SQL
val filteredViaSparkSql = sparkSession.sql("SELECT * FROM events WHERE user_id IS NOT NULL AND device_id IS NOT NULL")
Dataset API
val combinedViaDatasets = filteredViaDataset
.joinWith(devices, events("device_id") === devices("device_id"), "inner")
.map{ case (event: Event, device: Device) => EventWithDeviceInfo(
user_id=event.user_id.get,
device_id=device.device_id,
browser_type=device.browser_type,
os_type=device.os_type,
device_type=device.device_type,
referrer=event.referrer.getOrElse("unknow"),
host=event.host,
url=event.url,
event_time=event.event_time
) }
.map { eventWithDevice =>
// Convert browser_type to uppercase while maintaining immutability
eventWithDevice.copy(browser_type = eventWithDevice.browser_type.toUpperCase)
}
combinedViaDatasets.show(5)
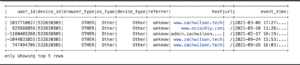
DataFrame API(不需要定義 case class,常用於動態 schema 或不確定欄位時)
val combinedViaDataFrames = filteredViaDataFrame.as("e")
.join(devices.as("d"), $"e.device_id" === $"d.device_id", "inner")
.select(
$"e.user_id",
$"d.device_id",
$"d.browser_type",
$"d.os_type",
$"d.device_type",
$"e.referrer",
$"e.host",
$"e.url",
$"e.event_time"
)
val rows= combinedViaDatasets.take(5)
rows.foreach(println)
combinedViaDataFrames.show(5)

Spark SQL (直觀,容易閱讀與維護)
filteredViaSparkSql.createOrReplaceTempView("filtered_events")
val combinedViaSparkSQL = spark.sql(f"""
SELECT
fe.user_id,
d.device_id,
d.browser_type,
d.os_type,
d.device_type,
fe. referrer,
fe.host,
fe.url,
fe.event_time
FROM filtered_events fe
JOIN devices d ON fe.device_id = d.device_id
""")
combinedViaSparkSQL.show(5)

| 觀點 | Dataset API | DataFrame API | Spark SQL |
|---|---|---|---|
| 型別安全 | ✅ 有 (Option[T] 提供編譯期檢查) |
❌ 無 | ❌ 無 |
| IntelliSense 支援 | ✅ 完整(case class 提供提示) | ❌ 弱(只靠欄位名稱) | ❌ 幾乎無 |
| 可讀性 | 中(有 .map、.joinWith 等 Scala 語法) |
中(類似 SQL,但欄位需加 $) |
✅ 高(最接近 SQL) |
| 維護性 | ✅ 高(compile-time check) | ❌ 易寫錯欄位名不報錯 | 中 |
| 靈活度 | ✅ 最佳(可搭配函數式編程) | ✅ 不錯 | ❌ 受限於 SQL 語法 |
| 實務適用時機 | 有明確 schema、穩定資料結構 | 欄位變動大、來源動態 | 給分析師、偏查詢導向情境 |