• 資料倉儲模型總覽|星型 vs 雪花 vs Graph 架構|Factless、Aggregate 與 Galaxy 實務比較
什麼是資料倉儲?
資料倉儲(Data Warehouse, DW) 是一個為 分析與決策 而建的集中式資料庫/平台,具備特色:
| 特性 | 說明 |
|---|---|
| 主題導向 | 依「銷售、客戶、財務」等主題整合資料,而非照業務系統分散存放 |
| 整合性 | 透過 ETL/ELT 流程,將來自 ERP、CRM、Log 等多源異構資料清洗、轉換、統一定義 |
| 時變性 | 儲存長期歷史資料,可追蹤趨勢、比較不同期間表現 |
| 不可更新 | 資料一旦進倉後多半僅讀取(Append-Only),避免線上交易鎖定衝突 |
| 支援 OLAP | 針對大量查詢、聚合、切片切塊優化,與 OLTP 系統分工 |
要讓資料倉儲真正發揮效益,正確的資料模型設計最關鍵──它決定了查詢效能、儲存成本、資料一致性與後續維運複雜度
下面六大資料倉儲模型:
- 星型架構(Star Schema)
- 雪花型架構(Snowflake Schema)
- 混合架構(Hybrid Schema)
- 無數值事實表(Factless Fact Table)
- 彙總事實表(Aggregate Fact Table)
- Galaxy 架構(Fact Constellation)
星型架構(Star Schema): 一個中心「事實表」直接連接多個「維度表」,結構扁平
資料量中等、查詢(JOIN)頻繁,用星型架構查詢會比較快。常見於電商平台訂單分析、超市POS銷售紀錄
-
優點:
查詢速度快(少 JOIN)
結構簡單,容易理解
適合 BI 工具 -
缺點:
維度表可能有重複資料(非正規化)
不利資料一致性與維護
範例:

產品維度表 product_dim p
| product_id | product_name | category |
|---|---|---|
| 1 | Apple | Fruit |
| 2 | Shampoo | Personal |
| 3 | Milk | Dairy |
顧客維度表 customer_dim c
| customer_id | customer_name | city |
|---|---|---|
| 101 | Alice | Taipei |
| 102 | Bob | Taichung |
| 103 | Carol | Kaohsiung |
日期維度表 date_dim d
| date_id | date | day_of_week |
|---|---|---|
| 20240701 | 2024-07-01 | Monday |
| 20240702 | 2024-07-02 | Tuesday |
| 20240703 | 2024-07-03 | Wednesday |
銷售事實表 sales_fact f
| sale_id | date_id | customer_id | product_id | quantity | revenue |
|---|---|---|---|---|---|
| 1 | 20240701 | 101 | 1 | 2 | 60 |
| 2 | 20240701 | 102 | 3 | 1 | 30 |
| 3 | 20240702 | 103 | 2 | 3 | 150 |
PS 這裡也可以從 sales_fact (假設有這些欄位),再拆出一個 Junk Dimension(雜項維度)表
修改後的 sales_fact f 表
| sale_id | date_id | customer_id | product_id | junk_flag_id | quantity | revenue |
|---|---|---|---|---|---|---|
| 1 | 20240701 | 101 | 1 | 3 | 2 | 60 |
| 2 | 20240701 | 102 | 3 | 1 | 1 | 30 |
| 3 | 20240702 | 103 | 2 | 2 | 3 | 150 |
junk_order_flag_dim j
| junk_flag_id | is_promo | is_first_purchase | channel |
|---|---|---|---|
| 1 | false | false | WEB |
| 2 | true | false | WEB |
| 3 | true | true | APP |
| 4 | false | true | STORE |
查詢每日銷售細節
SELECT
d.date,
c.customer_name,
p.product_name,
f.quantity,
f.revenue
FROM sales_fact f
JOIN date_dim d ON f.date_id = d.date_id
JOIN customer_dim c ON f.customer_id = c.customer_id
JOIN product_dim p ON f.product_id = p.product_id;
# 假設有 junk_order_flag_dim 表
JOIN junk_order_flag_dim j ON f.junk_flag_id = j.junk_flag_id;
雪花型架構(Snowflake Schema): 在星型架構基礎上,將維度表進一步正規化成多張細表
多筆 product_dim 都指向同一 category_id,避免重複儲存類別名稱 (參考下面範例)
長期資料量大時,節省空間效果越明顯,分類更新只需在一張表調整即可,不會破壞所有相關紀錄。常見於多層級地區(城市 → 州 → 國家)、產品分類(商品 → 類別 → 部門)
-
優點:
更節省儲存空間
維護一致性較佳 -
缺點:
查詢變慢(JOIN 增多)
結構複雜,學習曲線高
範例:(照前面的星形表拆分更細)
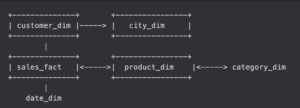
產品維度表 product_dim p (多拆出 產品類別維度表)
| product_id | product_name | category_id |
|---|---|---|
| 1 | Apple | 1 |
| 2 | Shampoo | 2 |
| 3 | Milk | 3 |
產品類別維度表 category_dim ca
| category_id | category_name |
|---|---|
| 1 | Fruit |
| 2 | Personal |
| 3 | Dairy |
顧客維度表 customer_dim c (多拆出 城市維度表)
| customer_id | customer_name | city_id |
|---|---|---|
| 101 | Alice | 10 |
| 102 | Bob | 20 |
| 103 | Carol | 30 |
城市維度表 city_dim ci
| city_id | city_name |
|---|---|
| 10 | Taipei |
| 20 | Taichung |
| 30 | Kaohsiung |
日期維度表 date_dim d
| date_id | date | day_of_week |
|---|---|---|
| 20240701 | 2024-07-01 | Monday |
| 20240702 | 2024-07-02 | Tuesday |
| 20240703 | 2024-07-03 | Wednesday |
銷售事實表 sales_fact f
| sale_id | date_id | customer_id | product_id | quantity | revenue |
|---|---|---|---|---|---|
| 1 | 20240701 | 101 | 1 | 2 | 60 |
| 2 | 20240701 | 102 | 3 | 1 | 30 |
| 3 | 20240702 | 103 | 2 | 3 | 150 |
查詢每個城市的銷售總額
SELECT
ci.city_name,
SUM(f.revenue) AS total_sales
FROM sales_fact f
JOIN customer_dim c ON f.customer_id = c.customer_id
JOIN city_dim ci ON c.city_id = ci.city_id
GROUP BY ci.city_name;
每個類別的銷售總額
SELECT
c.category_name,
SUM(f.revenue) AS total_sales
FROM sales_fact f
JOIN product_dim p ON f.product_id = p.product_id
JOIN category_dim ca ON p.category_id = ca.category_id
GROUP BY ca.category_name;
混合架構(Hybrid Schema): 同時使用星型與雪花型,依據需求決定正規化程度
計算/查詢頻繁,但某些維度重複度又極高,折衷「查詢效率」與「空間、省維護」
維度單純 -> 星型
維度變化頻繁、有階層性 -> 雪花
-
優點:
兼具效率與一致性
彈性高,易擴充 -
缺點:
管理較複雜
難以標準化
範例:(混合前面的星形表和雪花表)
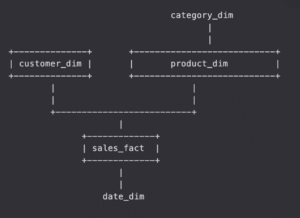
產品維度表 product_dim p (多拆出 產品類別維度表)(雪花結構)
| product_id | product_name | category_id |
|---|---|---|
| 1 | Apple | 1 |
| 2 | Shampoo | 2 |
| 3 | Milk | 3 |
產品類別維度表 category_dim ca (雪花結構)
| category_id | category_name |
|---|---|
| 1 | Fruit |
| 2 | Personal |
| 3 | Dairy |
顧客維度表 customer_dim c(保留星型結構)
| customer_id | customer_name | city |
|---|---|---|
| 101 | Alice | Taipei |
| 102 | Bob | Taichung |
| 103 | Carol | Kaohsiung |
日期維度表 date_dim d (保留星型結構)
| date_id | date | day_of_week |
|---|---|---|
| 20240701 | 2024-07-01 | Monday |
| 20240702 | 2024-07-02 | Tuesday |
| 20240703 | 2024-07-03 | Wednesday |
銷售事實表 sales_fact f
| sale_id | date_id | customer_id | product_id | quantity | revenue |
|---|---|---|---|---|---|
| 1 | 20240701 | 101 | 1 | 2 | 60 |
| 2 | 20240701 | 102 | 3 | 1 | 30 |
| 3 | 20240702 | 103 | 2 | 3 | 150 |
查詢每個類別每日銷售總額
SELECT
d.date,
ca.category_name,
SUM(f.revenue) AS total_sales
FROM sales_fact f
JOIN date_dim d ON f.date_id = d.date_id
JOIN product_dim p ON f.product_id = p.product_id
JOIN category_dim ca ON p.category_id = ca.category_id
GROUP BY d.date, ca.category_name;
Graph 資料模型(Graph Data Modeling)
- 優點:高度靈活(多跳查詢多層關係,例如:朋友的朋友、共同興趣的人、二度或三度網絡,非常快)、關聯直接以邊(Edge)形式建模、節點可含多個屬性,建模靈活
- 缺點:如需結合屬性分析(如群聚演算法、最短路徑)會很難操作、當關係越來越多,關聯 JOIN 的路徑和邏輯會變得難以維護和優化
| 元件 | 說明 |
|---|---|
| 節點(Vertex) | 實體,例如玩家、球隊、比賽、產品、城市等 |
| 邊(Edge) | 實體之間的關係,例如「參加了」、「贏過」 |
| 屬性(Properties) | 節點或邊所附加的資訊,如分數、時間等 |
範例:(使用者互相關注)
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name TEXT
);
CREATE TABLE user_follows (
follower_id INT REFERENCES users(user_id),
followee_id INT REFERENCES users(user_id),
follow_time TIMESTAMP,
PRIMARY KEY (follower_id, followee_id)
);
-- 使用者
INSERT INTO users (name) VALUES
('Alice'), -- user_id = 1
('Bob'), -- user_id = 2
('Carol'), -- user_id = 3
('David'), -- user_id = 4
('Eve'); -- user_id = 5
-- 關注關係(誰關注誰)
INSERT INTO user_follows (follower_id, followee_id, follow_time) VALUES
(1, 2, now()), -- Alice -> Bob
(2, 3, now()), -- Bob -> Carol
(3, 4, now()), -- Carol -> David
(1, 5, now()); -- Alice -> Eve
user
| user_id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
| 4 | David |
| 5 | Eve |
user_follower
| follower_id | followee_id | follow_time |
|---|---|---|
| 1 | 2 | now() |
| 2 | 3 | now() |
| 3 | 4 | now() |
| 1 | 5 | now() |
找出 Alice 的二度朋友(朋友的朋友)
SELECT
DISTINCT u2.name AS second_degree_friend
FROM users u1
JOIN user_follows f1 ON u1.user_id = f1.follower_id
JOIN user_follows f2 ON f1.followee_id = f2.follower_id
JOIN users u2 ON f2.followee_id = u2.user_id
WHERE u1.name = 'Alice';
| 別名 | 來源表 | 代表的意思 |
|---|---|---|
u1 |
users |
Alice 本人 |
f1 |
user_follows |
Alice 的 第一層關注(她關注的人) |
f2 |
user_follows |
Alice 的朋友的 關注對象(朋友的朋友) |
u2 |
users |
被朋友關注的對象 → 即為「二度朋友」 |
# 最終結果會是 Carol
Alice (u1)
↓ f1.followee_id
Bob
↓ f2.followee_id
Carol (u2)
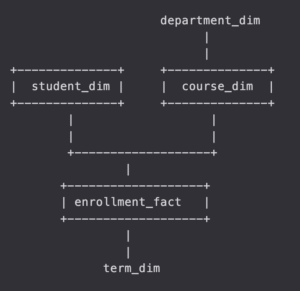
無數值事實表(Factless Fact Table): 事實表只記錄事件發生與否,沒有數值欄位
表結構簡單、大小極小(僅鍵),只能回答 是否發生 / 由誰發生 之類問題。常見於學生選課紀錄、員工打卡紀錄、使用者點擊紀錄
需要度量時,可在報表層做 COUNT(*) 或將欄位升級為 Aggregate Fact
-
優點:
資料精簡
適用於「是否發生」類問題 -
缺點:
不適合做加總分析
查詢分析須搭配維度表
範例:
學生維度表 student_dim s
| student_id | student_name | major |
|---|---|---|
| 1001 | Alice Chen | CS |
| 1002 | Bob Wang | Econ |
| 1003 | Carol Lin | Math |
科系維度表 department_dim d
| department_id | department_name |
|---|---|
| 10 | CS |
| 20 | Econ |
| 30 | Math |
課程維度表 course_dim c
| course_id | course_name | department_id |
|---|---|---|
| CS101 | Intro to Python | 10 |
| EC201 | Micro-Economics | 20 |
| MA301 | Linear Algebra | 30 |
學期維度表 term_dim t
| term_id | term_name |
|---|---|
| 2024S1 | 2024 Spring |
| 2024F1 | 2024 Fall |
報名事實表 enrollment_fact f
| student_id | course_id | term_id |
|---|---|---|
| 1001 | CS101 | 2024S1 |
| 1001 | MA301 | 2024S1 |
| 1002 | EC201 | 2024S1 |
| 1003 | CS101 | 2024F1 |
哪些學生在 2024 Spring 選過 CS 系課?
SELECT DISTINCT s.student_name
FROM enrollment_fact f
JOIN student_dim s ON f.student_id = s.student_id
JOIN course_dim c ON f.course_id = c.course_id
JOIN department_dim d ON c.department_id = d.department_id
JOIN term_dim t ON f.term_id = t.term_id
WHERE t.term_name = '2024 Spring'
AND d.department_name = 'CS';
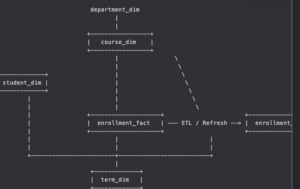
彙總事實表(Aggregate Fact Table): 詳細事實表的資料彙總
常見於報表與儀表板查詢、業務分析需求(如周/月彙總)
-
優點:
查詢速度極快
降低資料倉儲壓力 -
缺點:
資料非原始,不適合深層分析
彙總邏輯需一致,否則會誤導
範例:(照前面 Factless Fact Table 增加新表)
彙總查詢(科系總選課量)→ 只讀 enrollment_agg_fact,效能最佳
- enrollment_agg_fact a
| course_id | term_id | enrol_count |
|---|---|---|
| CS101 | 2024S1 | 1 |
| MA301 | 2024S1 | 1 |
| EC201 | 2024S1 | 1 |
| CS101 | 2024F1 | 1 |
- 2024 Spring 哪個科系的課最受歡迎?
SELECT d.department_name, SUM(a.enrol_count) AS total_enrolled FROM enrollment_agg_fact a JOIN course_dim c ON a.course_id = c.course_id JOIN department_dim d ON c.department_id = d.department_id JOIN term_dim t ON a.term_id = t.term_id WHERE t.term_name = '2024 Spring' GROUP BY d.department_name ORDER BY total_enrolled DESC;
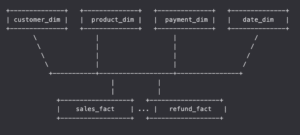
Galaxy 架構(Fact Constellation): 多張事實表共享同一組維度表,又稱「事實星群」
常見於
銷售事實 + 退款事實
出貨事實 + 收款事實
-
優點:
支援複雜商業流程
維度表重複利用,節省空間 -
缺點:
維度表需更細緻設計(避免衝突)
資料整合成本高
範例:
產品維度表 product_dim p
| product_id | product_name | category |
|---|---|---|
| 1 | Apple | Fruit |
| 2 | Shampoo | Personal |
| 3 | Milk | Dairy |
顧客維度表 customer_dim c
| customer_id | customer_name | city |
|---|---|---|
| 101 | Alice | Taipei |
| 102 | Bob | Taichung |
| 103 | Carol | Kaohsiung |
日期維度表 date_dim d
| date_id | date | day_of_week |
|---|---|---|
| 20240701 | 2024-07-01 | Monday |
| 20240702 | 2024-07-02 | Tuesday |
| 20240703 | 2024-07-03 | Wednesday |
付款維度表 payment_dim pa
| payment_id | method | provider |
|---|---|---|
| 9001 | credit_card | Visa |
| 9002 | credit_card | Master |
| 9003 | paypal | PayPal |
銷售事實表 sales_fact sf
| sale_id | date_id | customer_id | product_id | quantity | revenue | payment_id |
|---|---|---|---|---|---|---|
| 1 | 20240701 | 101 | 1 | 2 | 60 | 9001 |
| 2 | 20240701 | 102 | 3 | 1 | 30 | 9002 |
退款事實表 refund_fact rf
| refund_id | date_id | customer_id | product_id | qty_refund | refund_amt | sale_id (FK to sf.sale_id) |
|---|---|---|---|---|---|---|
| 501 | 20240705 | 101 | 1 | 1 | 30 | 1 |
2024 Q3(7–9 月)各付款方式的 淨營收(銷售 – 退款)
SELECT
pa.provider,
SUM(sf.revenue) -- 銷售總額
- COALESCE(SUM(rf.refund_amt), 0) -- 扣掉退款
AS net_revenue
FROM sales_fact sf
JOIN date_dim d ON sf.date_id = d.date_id
JOIN payment_dim pa ON sf.payment_id = pa.payment_id
-- 對應同一張銷售單的退款;rf.date_id 走 Q3 篩選
LEFT JOIN refund_fact rf
ON rf.sale_id = sf.sale_id
AND rf.date_id BETWEEN '20240701' AND '20240930'
WHERE d.date BETWEEN '2024-07-01' AND '2024-09-30' -- 銷售日期也限定 Q3
GROUP BY pa.provider
ORDER BY net_revenue DESC;