• 資料科學分類模型評估: 二元混淆矩陣、ROC 曲線、多元混淆矩陣
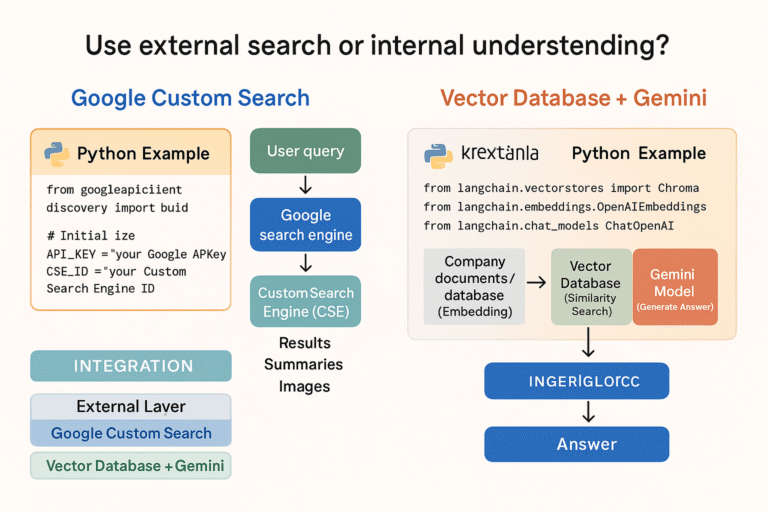
二元混淆矩陣 Confusion matrix
網路上圖片
最常聽到的案例通常是疾病預測、垃圾郵件分類…
以疾病預測為例
-
Accuracy 準確度
所有正確診斷的比例
= (TP+TN)/ TOTAL -
TPR, True Positive Rate 真陽性率
也稱為Sensitivity靈敏性、Recall召回率
所有真實為陽性中,被正確檢測為陽性的
= TP/(TP+FN),真陽性/(真正陽性+假陰性,其實為陽性) -
FNR, False Negative Rate 偽陰性率
所有真實為陽性中,被錯誤檢測為陰性的,越小越好
= FN/(TP+FN),假陰性,其實為陽性/(真正陽性+假陰性,其實為陽性) -
FPR, False Positive Rate 偽陽性率
所有真實為陰性中,被錯誤檢測為陽性的,越小越好
= FP/(FP+TN),假陽性,其實為陰性/(假陽性,其實為陰性+真陰性) -
TNR, True Negative Rate 真陰性率
也稱為Specificity特異性
所有真實為陰性中,被正確檢測為陰性的
= TN/(FP+TN),真陰性/(假陽性,其實為陰性+真陰性) -
PPV, Positive Predictive Value 陽性預測值
也稱為Precision精確率
所有被檢測為陽性中,實際為陽性的,越高越好
= TP/(TP+FP),真陽姓/(真陽姓+假陽性) -
FDR, False Discovery Rate 偽發現率
所有被檢測為陽性中,被錯誤檢測為陽性的
= FP/(TP+FP),假陽姓,實際為陰性/(真陽姓+假陽性) -
NPV, Negative Positive Value 陰性預測值
所有被檢測為陰性中,實際為陰性的,越高越好
= TN/(TN+FN),真陰姓/(真陰姓+假陰性) -
FOR, False Omission Rate 偽遺漏率
所有被檢測為陰性中,被錯誤檢測為陰性的
= FN/(TN+FN),假陰姓,實際為陽性/(真陰姓+假陰性) -
LR+ , Positive Likelihood Ratio 陽性似然比
陽性診斷的真實性
= LR+ = Sensitivity / (1−Specificity) -
LR- , Negative Likelihood Ratio 陰性似然比
性診斷的真實性
= LR- = (1−Sensitivity) / Specificity
-
DOR , Diagnostic Odds Ratio 診斷優勢比
陽性似然比與陰性似然比的比值
= LR+ / LR− -
𝐹1 Score
靈敏度和陽性預測值的調和平均數
= (2SensitivityPrecision) / (Sensitivity + Precision)
= (2TPRPPV) / (TPR + PPV) -
G-measure
靈敏度和特異度的幾何平均數
= Sensitivity Specificity 開根號
= (sensitivity specificity) ** 0.5
練習:癌症判斷
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
import numpy as np
#
np.random.seed(0)
X = np.random.rand(10, 2) # 10個樣本,每個樣本兩個特徵
y = np.random.randint(0, 2, 10) # 0健康 1有癌症
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 邏輯回歸 二元分類
model = LogisticRegression()
model.fit(X_train, y_train)
# 預測概率
y_pred_proba = model.predict_proba(X_test)[:, 1]
print("預測概率:")
print(y_pred_proba)
print() # 預測為0的機率0.73,預測為1的機率0.75
y_pred = model.predict(X_test)
# 混淆矩陣
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(cm)
print()
# 分類報告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))

#
TP = cm[1, 1]
TN = cm[0, 0]
FP = cm[0, 1]
FN = cm[1, 0]
accuracy = (TP + TN) / (TP + TN + FP + FN)
# TPR
sensitivity = TP / (TP + FN)
# TNR
specificity = TN / (FP + TN)
# PPV
precision = TP / (TP + FP)
#
recall = sensitivity
# F1 = (2*TPR*PPV) / (TPR + PPV)
f1_score = (2 * sensitivity * precision) / (sensitivity + precision)
# FNR
fnr = FN / (TP + FN)
# FPR
fpr = FP / (FP + TN)
#
ppv = precision
# FDR
fdr = FP / (TP + FP)
# NPV
npv = TN / (TN + FN)
# FOR
for_ = FN / (TN + FN)
# LR+ = = Sensitivity / (1−Specificity)
lr_plus = sensitivity / (1 - specificity)
# LR- = (1−Sensitivity) / Specificity
lr_minus = (1 - sensitivity) / specificity
# DOR
dor = lr_plus / lr_minus
# g_measure
g_measure = (sensitivity * specificity) ** 0.5
print("\nAccuracy:", accuracy)
print("Sensitivity (TPR):", sensitivity)
print("Specificity (TNR):", specificity)
print("Precision (PPV):", precision)
print("Recall (TPR):", recall)
print("F1 Score:", f1_score)
print("FNR:", fnr)
print("FPR:", fpr)
print("FDR:", fdr)
print("NPV:", npv)
print("FOR:", for_)
print("LR+:", lr_plus)
print("LR-:", lr_minus)
print("DOR:", dor)
print("G-measure:", g_measure)
# LR+ = 真陽性率(TPR,也稱為靈敏度)/ 假陽性率(FPR),表示陽性結果的似然性是陰性結果的3.33倍
# LR- = 假陰性率(FNR)/ 真陰性率(TNR,也稱為特異性),表示陰性結果的似然性是陽性結果的0.22
# DOR 值較高時,表示測試的準確性較高
# G-measure 是敏感度(真陽性率)和特異度(真陰性率)的幾何平均值,越接近1表示測試的表現越好

ROC 曲線 (Receiver Operating Characteristic Curve)
先設置一個閥值
當訊號偵測(或變數測量)的結果是一個連續值時,類與類的邊界必須用一個閾值(英語:threshold)來界定。舉例來說,用血壓值來檢測一個人是否有高血壓,測出的血壓值是連續的實數(從0~200都有可能),以收縮壓140/舒張壓90為閾值,閾值以上便診斷為有高血壓,閾值未滿者診斷為無高血壓。可能有四種結果:
真陽性(TP):診斷為有,實際上也有高血壓
偽陽性(FP):診斷為有,實際卻沒有高血壓
真陰性(TN):診斷為沒有,實際上也沒有高血壓
偽陰性(FN):診斷為沒有,實際卻有高血壓
這時可以繪製 ROC曲線
X 軸:偽陽性率 (FPR)
Y 軸:真陽性率 (TPR)
好的模型會在假陽性率較低的情況下有較高的真陽性率,使ROC曲線盡可能靠近左上角
AUC (Area Under the Curve)
AUC 是 ROC 曲線下的面積,是一個從 0 到 1 的值,用來量化模型的整體性能
AUC = 1:完美分類器,模型對所有正樣本和負樣本都能正確分類
AUC = 0.5:隨機猜測,模型無法區分正樣本和負樣本,其性能相當於隨機猜測
AUC < 0.5:這種情況很少見,
假設有一個分類模型,經過多次不同閾值的設定,我們得到以下幾組 TPR 和 FPR:
閾值 = 0.9:TPR = 0.2, FPR = 0.1
閾值 = 0.7:TPR = 0.5, FPR = 0.3
閾值 = 0.5:TPR = 0.8, FPR = 0.4
閾值 = 0.3:TPR = 0.9, FPR = 0.6
根據這些數據繪製出ROC曲線,將點 (FPR, TPR) 繪製在圖表上,連接這些點就得到ROC曲線。接著計算AUC,AUC值越接近1分類性能越好
import matplotlib.pyplot as plt
from sklearn.metrics import auc
# 定義 FPR 和 TPR
fpr = [0.1, 0.3, 0.4, 0.6]
tpr = [0.2, 0.5, 0.8, 0.9]
# 計算 AUC
roc_auc = auc(fpr, tpr)
# 繪製 ROC 曲線
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()

AUC 值為0.30,表示這個模型在區分陽性和陰性樣本方面表現不佳,可以考慮調整模型的參數、選擇不同的特徵或使用不同的算法
練習:癌症判斷
上面的癌症分類結果便可繪製成
# ROC Line
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)
#
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()

儘管 AUC 值為 1.0,但其他指標顯示模型在特定閾值下的表現並不理想
Accuracy(準確率): 0.5
Sensitivity (TPR, Recall)(靈敏度/召回率): 1.0,指模型能正確識別所有陽性樣本
Specificity (TNR)(特異性): 0.0,指模型完全無法識別所有陰性樣本
Precision (PPV)(精確率): 0.5,正確預測為陽性的比例為 50%
F1 Score: 0.6667,2 (Precision Recall) / (Precision + Recall)
False Negative Rate (FNR)(假陰性率): 0.0,沒有樣本被錯誤預測為陰性
False Positive Rate (FPR)(假陽性率): 1.0,所有陰性的樣本都被錯誤預測為陽性
False Discovery Rate (FDR)(假發現率): 0.5,預測為陽性中,實際為陰性的比例
Negative Predictive Value (NPV)(陰性預測值): nan,因為沒有真實的負樣本,無法計算
False Omission Rate (FOR)(假遺漏率): nan,因為沒有真實的負樣本,無法計算
Positive Likelihood Ratio (LR+)(陽性似然比): 1.0,表示陽性結果的似然性
Negative Likelihood Ratio (LR-)(陰性似然比): nan,特異性為 0,無法計算
G-measure: 0.0,特異性為 0,無法計算
多元混淆矩陣 Multiclass Confusion Matrix
練習:鳶尾花分類
之前練習過的鳶尾花,總共有三種類別,這時就適用於多元混淆矩陣
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.ensemble import RandomForestClassifier
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
# 計算混淆矩陣
cm = confusion_matrix(y_test, y_pred)
#
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=iris.target_names)
disp.plot(cmap=plt.cm.Blues)
plt.title('Confusion Matrix for Iris Dataset')
plt.show()

from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Macro Average(宏平均),precision = (1+1+1)/3 = 1
# Weighted Average(加權平均)= ((1*19)+(1*13)+(1*13))/(19+13+13) = 1